Konfiguration von SQL Server Always-On-Basisverfügbarkeitsgruppen
Schritt für Schritt zur Hochverfügbarkeit
Always On-Basis-Verfügbarkeitsgruppen ist eine Lösung zur Hochverfügbarkeit von einzelnen Datenbanken ab SQL Server 2016 Standard Edition. Sie ersetzen das veraltete Feature „Datenbankspiegelung“ und bieten einen ähnlichen Funktionsumfang. Basis-Verfügbarkeitsgruppen ermöglichen einer primären Datenbank, ein einzelnes Replikat beizubehalten. Dieses Replikat kann entweder den synchronen Commit-Modus oder den asynchronen Commit-Modus verwenden, je nachdem, wie aktuell das Replikat jeweils sein muss.
Einschränkungen
Basis-Verfügbarkeitsgruppen bieten – verglichen mit den erweiterten Verfügbarkeitsgruppen der Enterprise Edition- nur einen Teil der Funktionen. Sie beinhalten die folgenden Einschränkungen:
- Beschränkung auf zwei Replikate (primäres und sekundäres)
- Kein Lesezugriff auf das sekundäre Replikat.
- Keine Datensicherung auf dem sekundären Replikat.
- Nur eine Datenbank pro Basis-Verfügbarkeitsgruppe
Basis-Verfügbarkeitsgruppen nutzen genauso wie die erweiterten Verfügbarkeitsgruppen das Windows Failover Cluster Feature, was also als erster Schritt eingerichtet werden müsste. Anschließend muss man beim SQL Dienst die Always On-Verfügbarkeitsgruppen aktivieren, und danach lassen sich die Basis-Verfügbarkeitsgruppen einrichten. Das kann mit dem SQL Server Management Studio ab Version 17.9.2 direkt über den Wizard für neue Verfügbarkeitsgruppen erfolgen.
Windows Failover Cluster einrichten
Über den Server Manager den „Assistenten zum Hinzufügen von Rollen und Features“ starten.
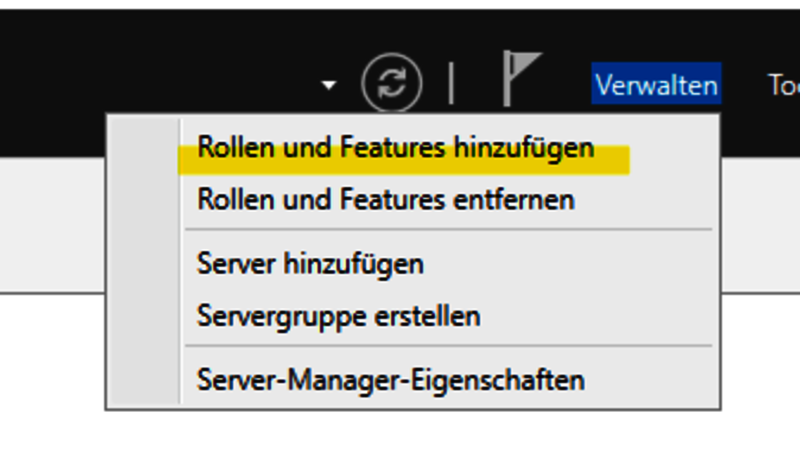
Unter dem Punkt „Features“ ist das „Failoverclustering“ zu finden, dies muss auf beiden Servern aktiviert werden. Nach dem Aktivieren ist ein Serverneustart erforderlich.

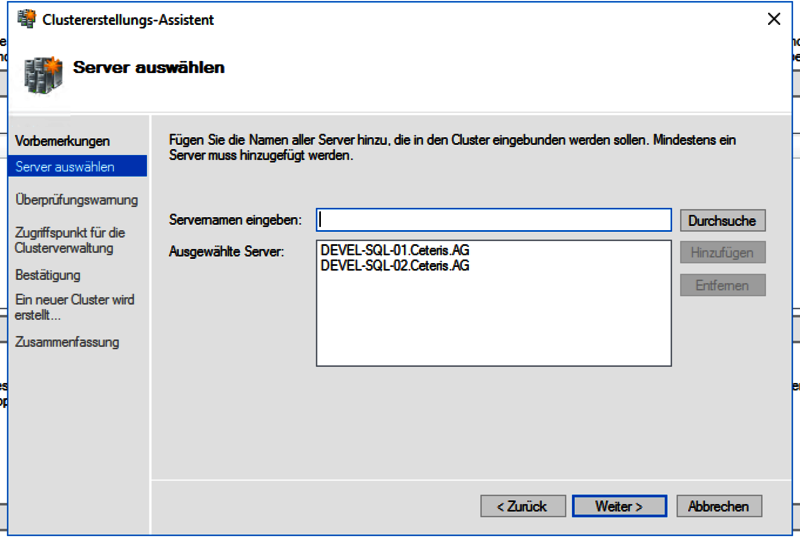
Nach dem Neustart auf einem der Server den Failover Cluster Manager aufrufen und hier den Wizard „Cluster erstellen“ starten

Im ersten Schritt fügt man nun die beiden Clusterknoten hinzu
Bei der Überprüfungswarnung ist es sinnvoll die Option „Nein“ auszuwählen und so die Prüftests zu überspringen

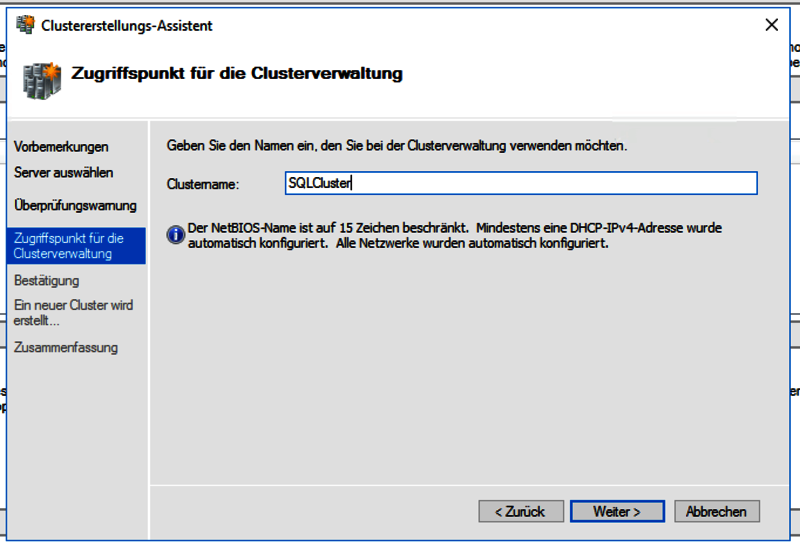
Im letzten Schritt wird noch der Clustername festgelegt. Falls beide Server via DHCP ihre IP-Adressen bekommen, so wird auch die IP-Adresse für den Cluster automatisch vergeben, ansonsten gibt es auch die Möglichkeit manuell eine IP-Adresse einzutragen. Anschließend wird der Cluster als neues Computerobjekt im AD angelegt.
Achtung! Für das Erstellen eines Clusters braucht man im AD das Recht neue Computerobjekte zu erstellen; in der OU, in welcher sich die beiden Server befinden. Eine genaue Beschreibung hierzu kann man hier finden: Konfigurieren von Clusterkonten in Active Directory | Microsoft Learn
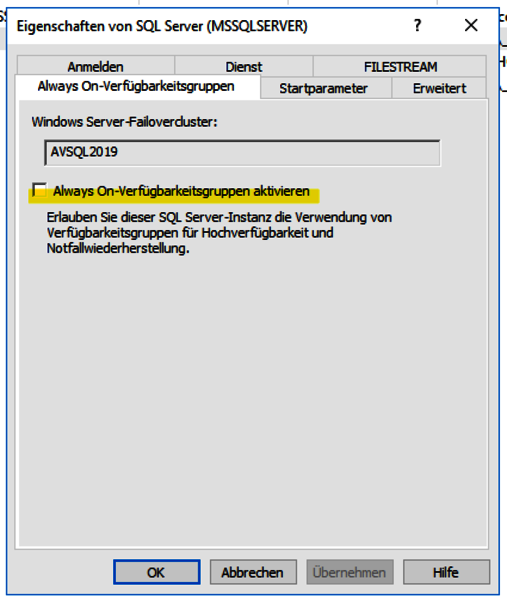
Aktiveren von Always On-Verfügbarkeitsgruppen
Nach dem obligatorischen Neustart muss nun auf beiden Servern der SQL Server Configuration Manager gestartet werden.
Hier nun unter dem Punkt „SQL Server-Dienste“ den SQL Server auswählen und mittels rechter Maustaste die Eigenschaften öffnen.

Im Reiter Always On-Verfügbarkeitsgruppen nun die Option „Always On-Verfügbarkeitsgruppen aktivieren“ auswählen. Anschließend muss der SQL Server Dienst neugestartet werden
Always On-Basisverfügbarkeitsgruppen einrichten
Das SQL Server Management Studio starten und mit dem gewünschten primären SQL Server verbinden.
Den „Assistenten für neue Verfügbarkeitsgruppen“ unter dem Punkt „Hochverfügbarkeit mit Always On“ starten.
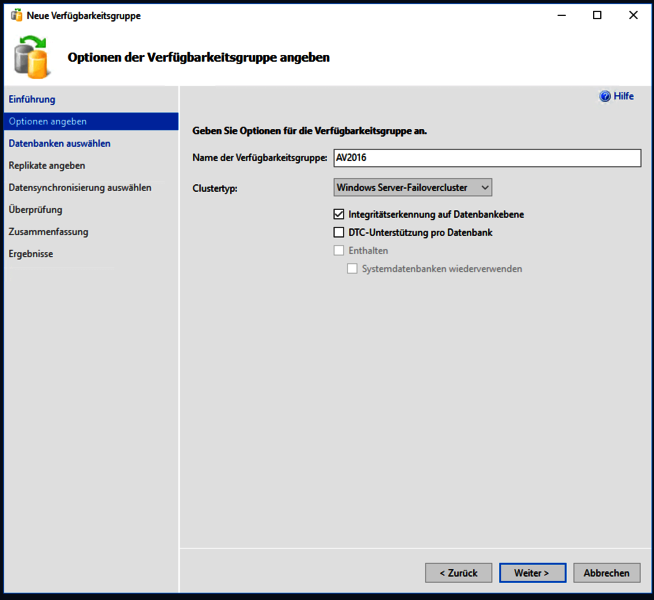
Hier nun als ersten den Namen der Verfügbarkeitsgruppe festlegen, außerdem als Clustertyp den Windows Failovercluster wählen und die „Integritätserkennung auf Datenbankebene“ aktivieren.
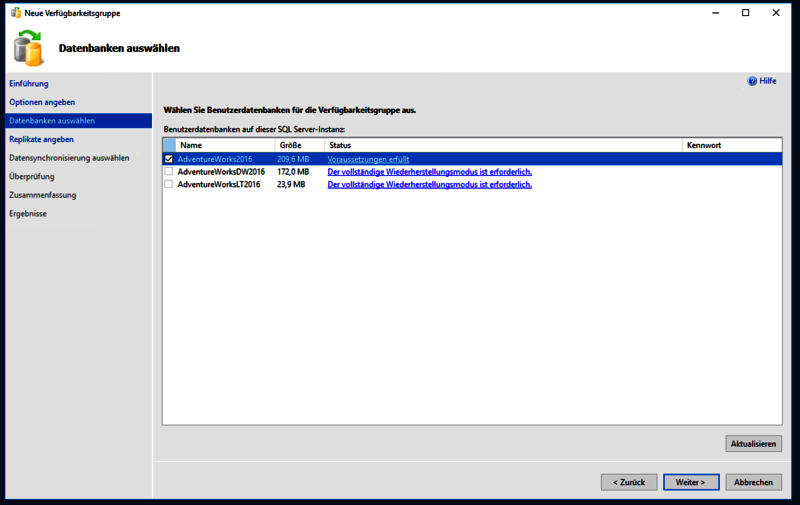
Anschließend die Datenbank auswählen, die in die Verfügbarkeitsgruppe aufgenommen werden soll. Hier kann nur eine Datenbank gewählt werden, weil wir ja eine Basisverfügbarkeitsgruppe einrichten. Die Datenbank muss den Wiederherstellungsmodus oder Recovery Model „vollständig“ nutzen.
Nun muss man noch den zweiten Server als Replikatsserver festlegen und sollte die Option für das automatische Failover aktivieren.
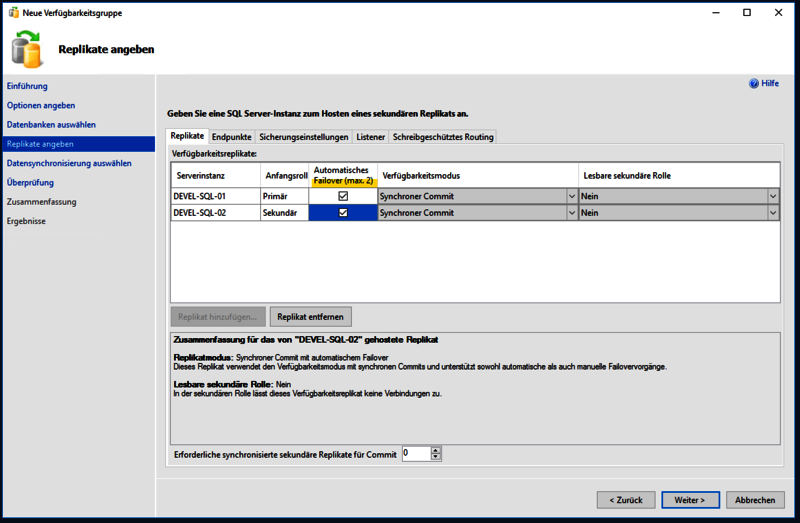
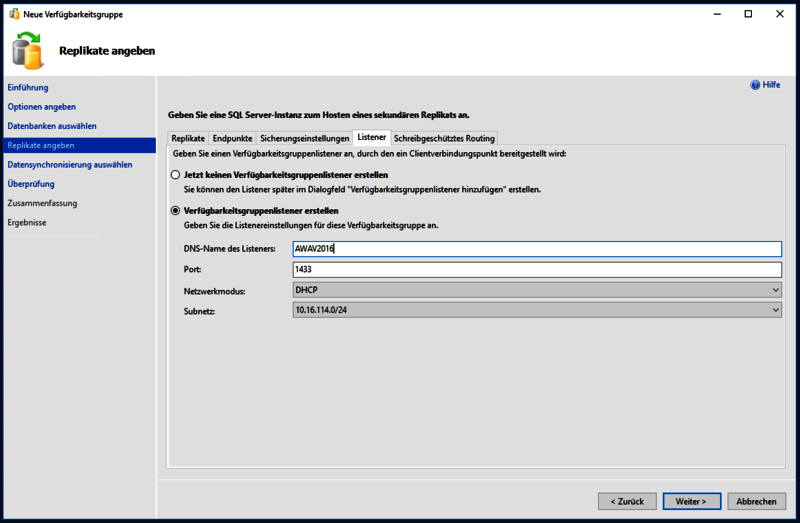
Im gleichen Schritt gibt es noch den Reiter „Listener“, dieser muss als nächstes konfiguriert werden. Hier wird der Name festgelegt, unter welchen die Datenbank später erreichbar ist, außerdem der Port und die IP.
Achtung! Für das Erstellen eines Listeners, braucht das Failovercluster-Computerkonto im AD das Recht neue Computerobjekte zu erstellen. Eine genaue Beschreibung hierzu kann man hier finden: Konfigurieren des Verfügbarkeitsgruppenlisteners – SQL Server Always On | Microsoft Learn
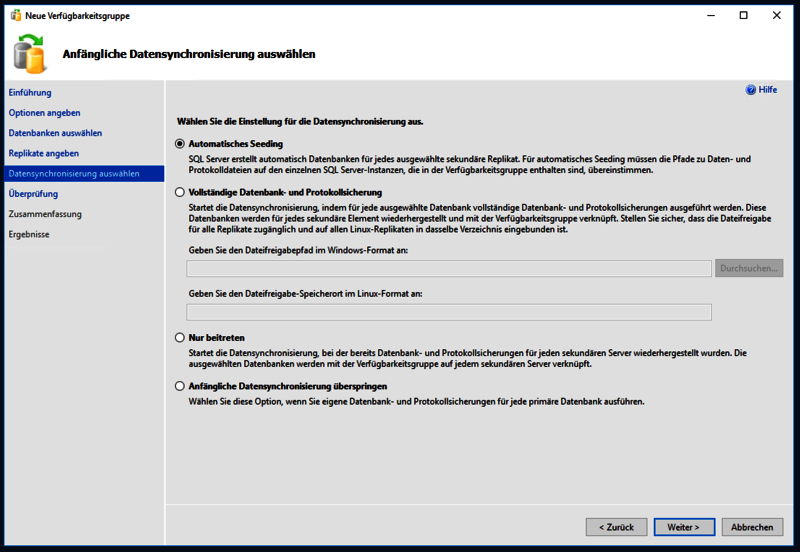
Nun muss nur noch ausgewählt werden, wie initial die Daten synchronisiert werden sollen. Hier empfiehlt es sich das automatische Seeding zu nutzen.
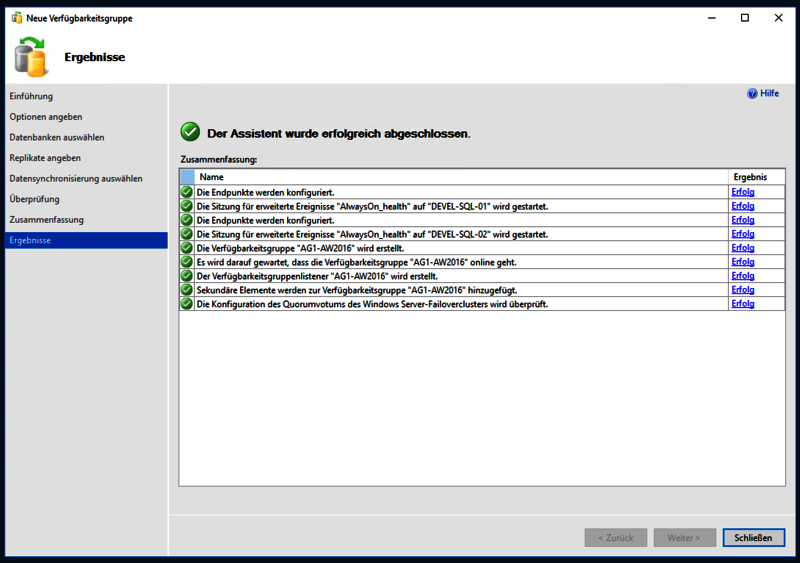
Nach der Überprüfung noch fertigstellen, und die Basisverfügbarkeitsgruppe und der Listener werden erstellt, und die Datenbank ist damit hochverfügbar.
Zurück zu Aktuelle News