Willkommen im Data Lake-Zeitalter: OneLake in Microsoft Fabric
Man interessiert sich vielleicht erst mal nur für Microsoft Fabric, weil es „der Nachfolger von Power BI“ ist. Manche interessieren sich nur deshalb dafür, weil sie eine Power BI Premium-Kapazität haben und jetzt merken, dass die jetzt alle auf Fabric-Kapazitäten umgestellt werden müssen. Aber tief innen drin in Fabric lebt etwas, was das Potenzial hat, den Umgang mit Daten in jeder Organisation zu verändern: der OneLake!
Jeder, der mit Fabric eine Lösung baut – und laut Microsoft sind das vor allem Fachanwender – arbeitet mit daran, den OneLake zu füllen.
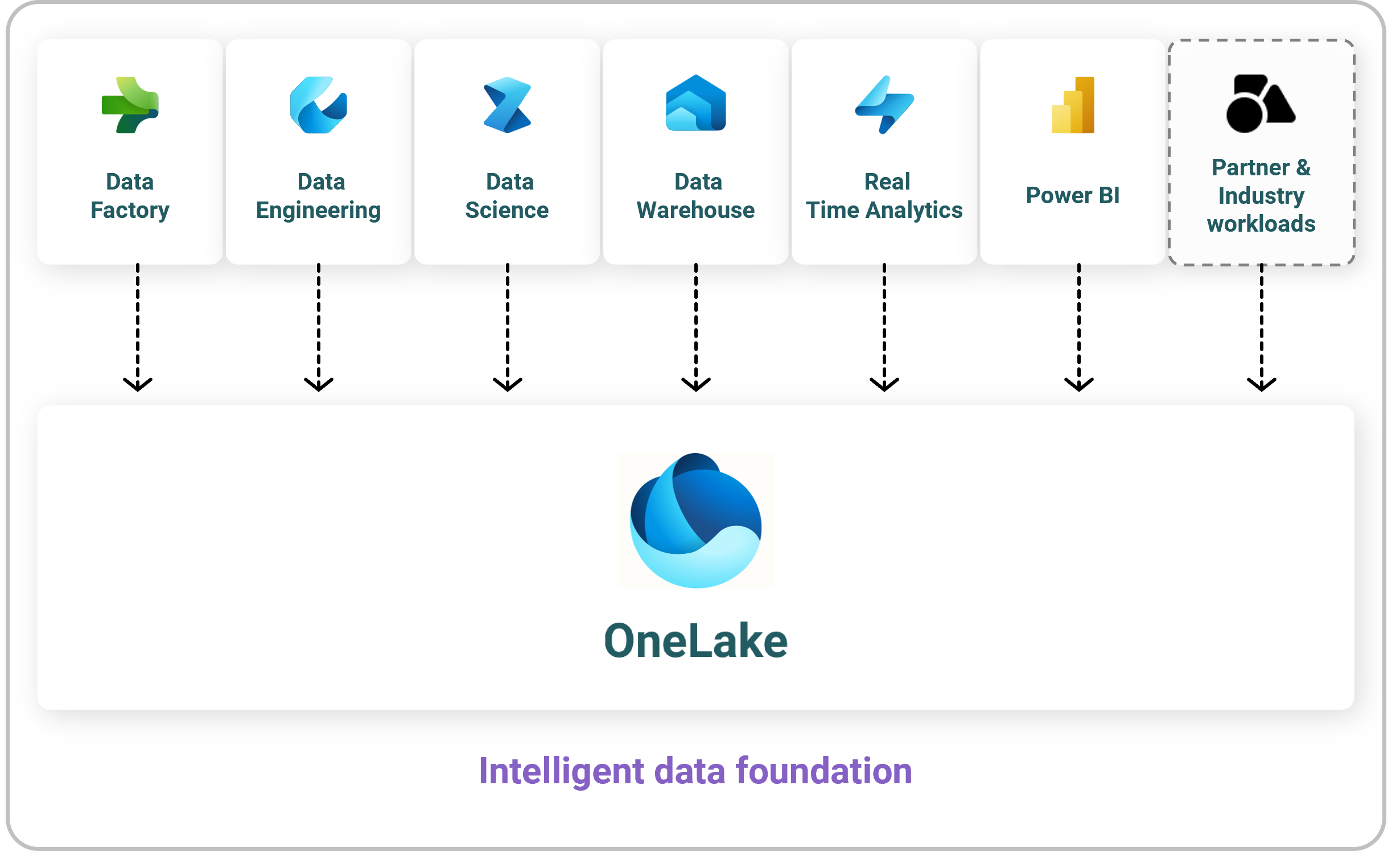
Es gibt pro Azure Tenant auch nur einen OneLake, also nicht wie früher: „einen für Controlling und einen für HR“, sondern wirklich nur eine einheitliche Datensenke für analytische Daten in der Organisation. Das Prinzip ist abgeleitet vom Konzept des Data Lake, also einem kostengünstigen Speicher -meist in einer Cloud - auf der alle Abteilungen ihre Daten zum Zweck der Auswertung ablegen können. Das muss so einfach und preiswert sein, dass sich das Ablegen schon lohnt, auch wenn man noch keinen konkreten Zweck und keinen klaren Use Case hat, denn das kommt dann schon noch!
Und hier setzt auch der OneLake an. Egal, was man mit Fabric macht: am Ende erzeugt man (mehr oder weniger) saubere, gut lesbare und strukturierte Daten an einem zentral erreichbaren Ort. Dieser Ort ist auch nicht völlig unstrukturiert (wie man es manchen Data Lakes vorwirft), sondern er besteht aus den Daten verschiedener Domänen (und das wären dann z.B. Controlling, HR, Produktion etc.) Innerhalb der Domänen gibt es dann die Arbeitsbereiche (Workspaces), die auch schon von Power BI bekannt sind, und dazu kann man sich die Faustregel merken: einen Arbeitsbereich pro Projekt! Damit vermeidet man, dass der Datensee sich schnell in einen Datensumpf verwandelt.
Natürlich sind diese Daten, die da einträchtig nebeneinander liegen, dadurch noch nicht integriert. Es gibt z.B. noch keine einheitlichen Stammdaten, oder keine übergreifenden Namenskonventionen! Aber Datenintegration ist wirklich sehr viel einfacher, wenn schon alles im OneLake liegt. So kann man etwa mit SQL oder mit grafischen Abfragen in Power BI schnell herausfinden, wo sich etwas leicht vergleichbar machen lässt und wo nicht.
Shortcuts oder “Verknüpfungen”
Wie komme ich jetzt in meinem Projekt-Arbeitsbereich an Daten aus einer anderen Domäne heran? Nochmal hineinkopieren nicht nötig: ich kann einfach die wichtigen Tabellen als Verknüpfung in meinen Arbeitsbereich holen. Dabei wird nichts kopiert, sondern es werden nur die Informationen gespeichert, wie ich an die Daten an einer anderen Stelle im OneLake herankomme. Sie erscheinen dann in meinem OneLake genauso, als ob sie hier liegen würden, werden aber direkt an der Quelle angesprochen.
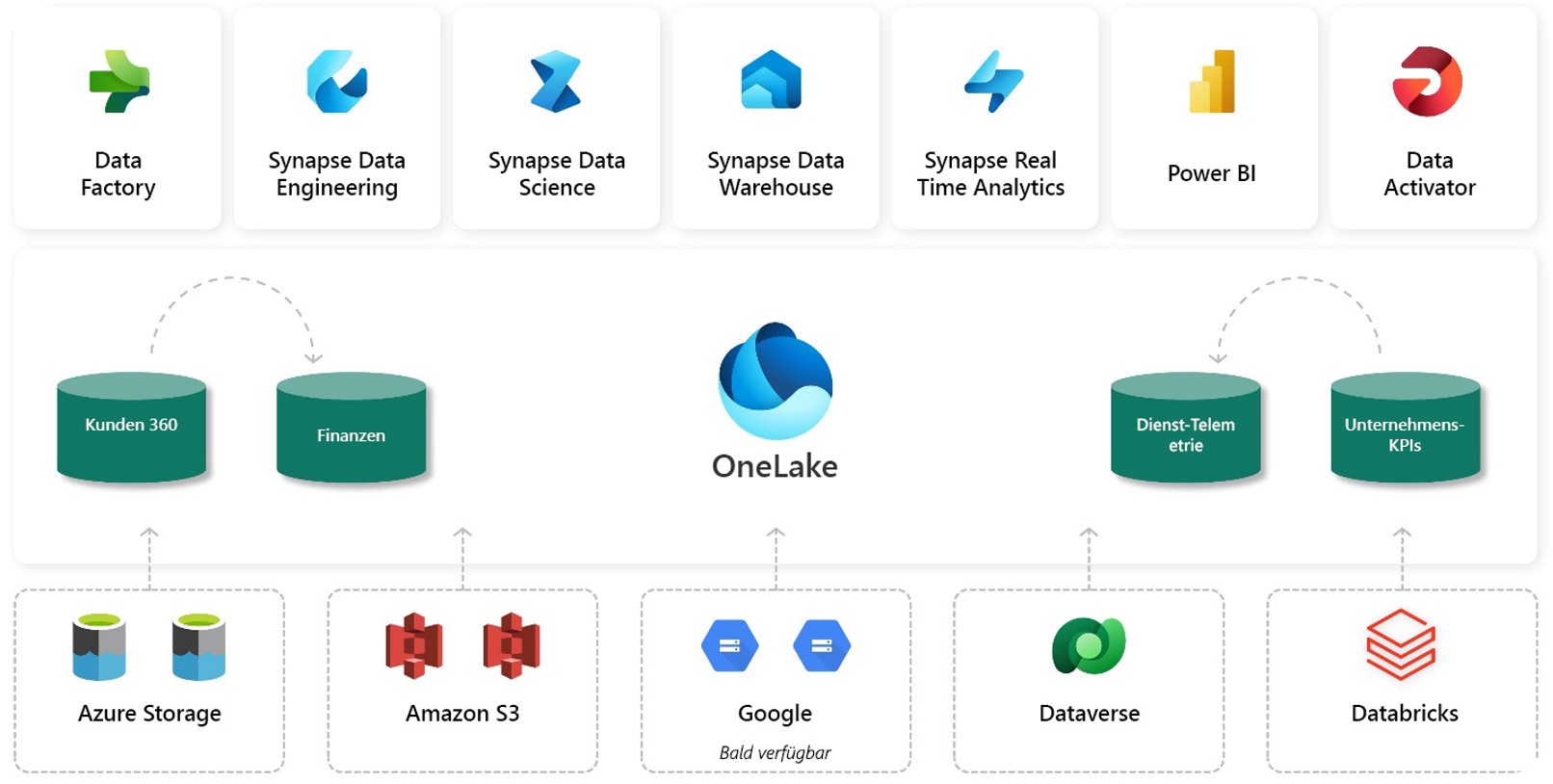
Multi-Cloud Data Lake
Man sieht also: der OneLake hat das Zeug, zum Beispiel vorhandene Data Warehouses zu erweitern und sogar abzulösen. Aber bei Data Lakes ist Microsoft ja nicht besonders früh dran oder innovativ! Viele Firmen haben bereits Daten in anderen Data Lakes, etwa in Amazon S3 Buckets oder in der Google Cloud.Aber auch dorthin kann man ganz einfach eine Verknüpfung erstellen, und damit ist OneLake offiziell der erste Multi-Cloud Data Lake!
Datenbankspiegelung oder „Mirroring“
Microsoft arbeitet unermüdlich daran, möglichst viele Daten möglichst einfach im OneLake zur Analyse auftauchen zu lassen. Viele Quellen aber sind kein Data Lake, sondern eher eine Datenbank wie SQL Server oder Oracle, was ist mit denen? Dafür gibt es die Datenbankspiegelung: Fabric nimmt die Tabellen, die man zur Analyse auswählt, und kopiert sie in den OneLake. Und danach werden alle Änderungen an diesen Tabellen in der Quelle quasi in Echtzeit auch im OneLake durchgeführt, ganz automatisch! Dazu werden die „Change Data Capture“-Fähigkeiten genutzt, die viele Datenbanken schon mitbringen.
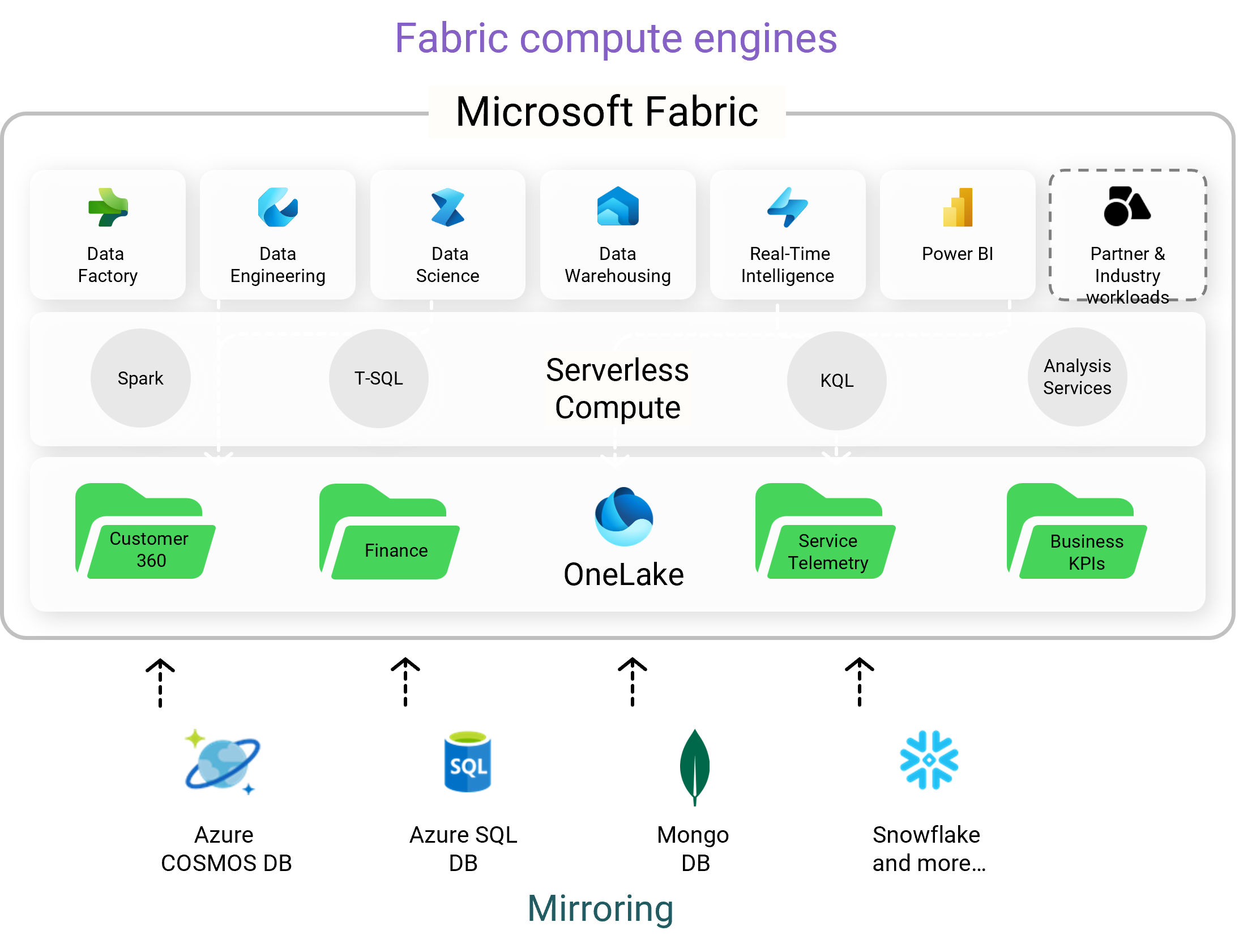
Aktuell werden nur der SQL Server in Azure, MongoDB, Snowflake und Cosmos DB unterstützt, aber natürlich ist auch der SQL Server „on premise“ vorne auf der Roadmap!
Und das Beste zum Schluss: die Daten-kopien, die die Spiegelung im OneLake anlegt, sind kostenlos, die Spiegelung frisst uns nicht die Leistung unserer Fabric-Kapazität weg. Man lernt daraus: der OneLake ist die Zukunft der Datenanalyse, also wird es Zeit, sich auf ihn einzustellen und sein Potential aktiv zu nutzen!

Für weitere Informationen über Microsoft Fabric und zukünftige Kurse kontaktieren Sie uns gerne!

Zurück zu Aktuelle News